#
Cluster là gì
Trước đây, các máy được sử dụng để tính toán hiệu năng cao được gọi là "siêu máy tính" hoặc các máy độc lập lớn có phần cứng chuyên dụng, rất khác với những gì bạn thấy ở máy tính ở nhà và văn phòng.
Tuy nhiên, ngày nay, phần lớn các siêu máy tính thay vào đó là các cluster (hay gọi tắt là "Cluster") --- tập hợp các máy tính độc lập được nối mạng với nhau. Các máy tính được kết nối với nhau này được trang bị phần mềm để điều phối các chương trình trên (hoặc trên) các máy tính đó và do đó chúng có thể làm việc cùng nhau để thực hiện các tác vụ tính toán chuyên sâu.
Các hệ thống tính toán cung cấp phần lớn là các cụm. Mỗi máy tính trong cụm được gọi là một node (thuật ngữ "Node" xuất phát từ lý thuyết đồ thị) và chúng ta thường nói về hai loại nút: head node và compute nodes.
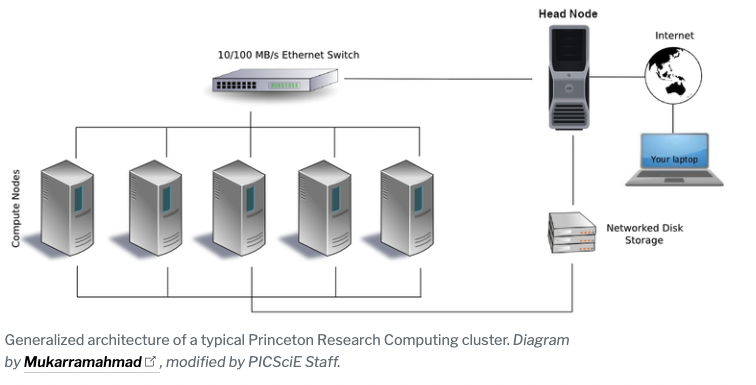
Để sử dụng hiệu quả, bạn nên biết về cluster structure của cluster mà mình sử dụng. Thông tin về từng cluster có thể tìm đọc chi tiết
Selab - Phòng thí nghiệm SELAB
#
Thuật ngữ sử dụng
- Job - ám chỉ một công việc hoặc tác vụ chạy tự động, thường là kết quả thực thi 1 đoạn mã nguồn
- Head node - là máy tính nơi chúng ta truy cập khi đăng nhập vào cluster. Đây là nơi chúng tôi chỉnh sửa tập lệnh, biên dịch mã và gửi công việc tới bộ lập lịch. Các head nodes được chia sẻ với những người dùng khác và các JOB không được chạy trên head nodes.
- Compute node - là các máy tính nơi các công việc sẽ được thực hiện. Để chạy các công việc trên các compute nodes, chúng ta phải thông qua bộ lập lịch. Bằng cách gửi JOB tới job scheduler, công việc sẽ tự động được chạy trên các compute node sau khi có sẵn các tài nguyên được yêu cầu. Chúng tôi sử dụng SLURM làm chương trình lập kế hoạch. Đọc thêm tại Slurm Workload Manager - Overview (schedmd.com)
- Core - Một cách viết tắt để chỉ số lượng lõi CPU của bộ xử lý (thường là vật lý) của chip CPU trong một nút. CPU của máy tính giống như bộ não của máy tính; nó xử lý và thực hiện phần lớn công việc mà chúng ta yêu cầu máy tính thực hiện.
#
HPC Cluster hoạt động thế nào?
Để chương trình của bạn chạy trên Cluster, bạn có thể bắt đầu công việc trên head node. Một công việc bao gồm các tập tin sau:
- Mã nguồn (source code) của chương trình của bạn
- SLURM script, sẽ yêu cầu các tài nguyên mà công việc của bạn yêu cầu về dung lượng bộ nhớ, số lõi, số node, v.v. Như đã đề cập trước đó, hệ thống sử dụng job-scheduler có tên SLURM.
Sau khi tệp của bạn được gửi, bộ lập lịch (SLURM) sẽ đảm nhiệm việc tìm hiểu xem tài nguyên bạn yêu cầu có sẵn trên các compute nodes hay không và nếu không, nó sẽ bắt đầu dự trữ các tài nguyên đó cho bạn. Khi tài nguyên có sẵn, bộ lập lịch sẽ chạy chương trình của bạn trên các compute nodes